Introduction
Reasoning models have achieved significant advancements in handling complex tasks, often surpassing traditional large language models. However, the challenge of overthinking remains common, significantly hindering computational efficiency. This issue arises as models produce an excess of redundant tokens that contribute little to the accuracy of answers, particularly in simpler tasks, resulting in considerable waste of resources.
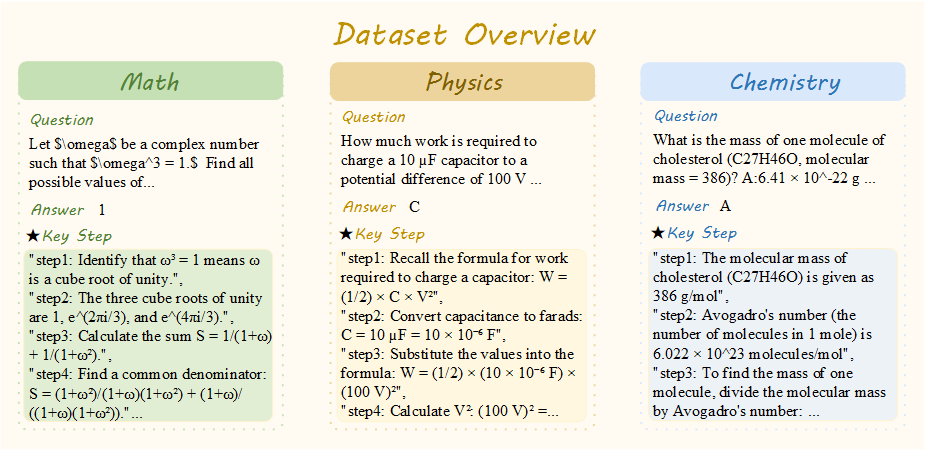
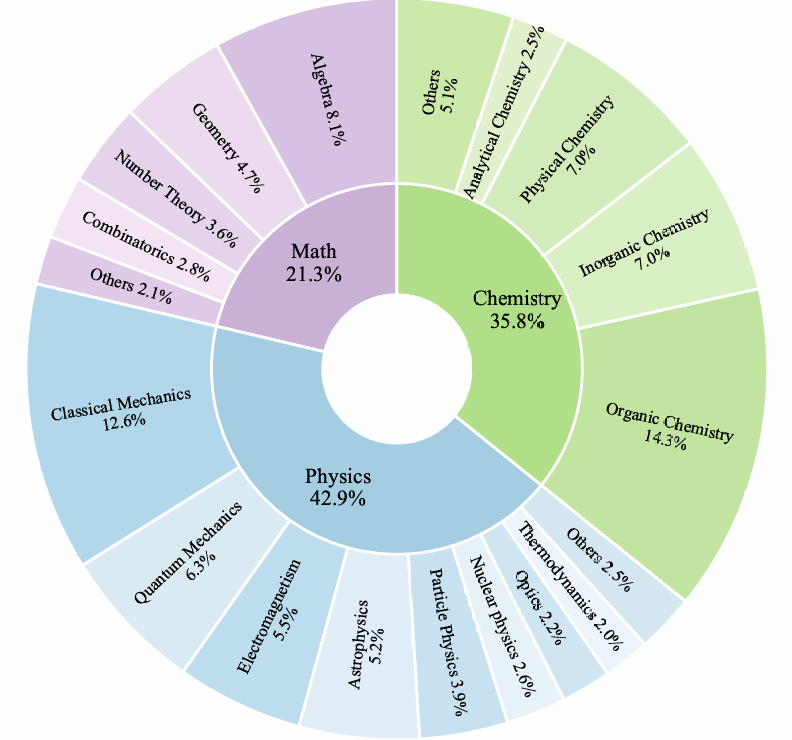
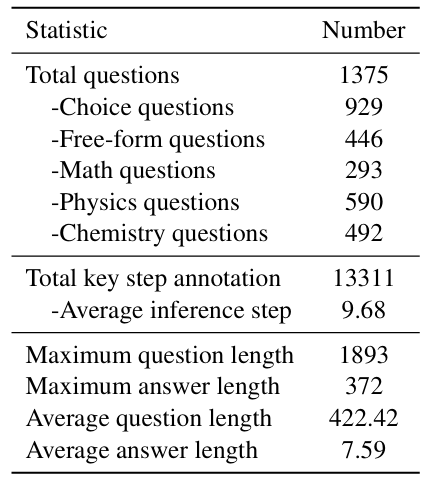
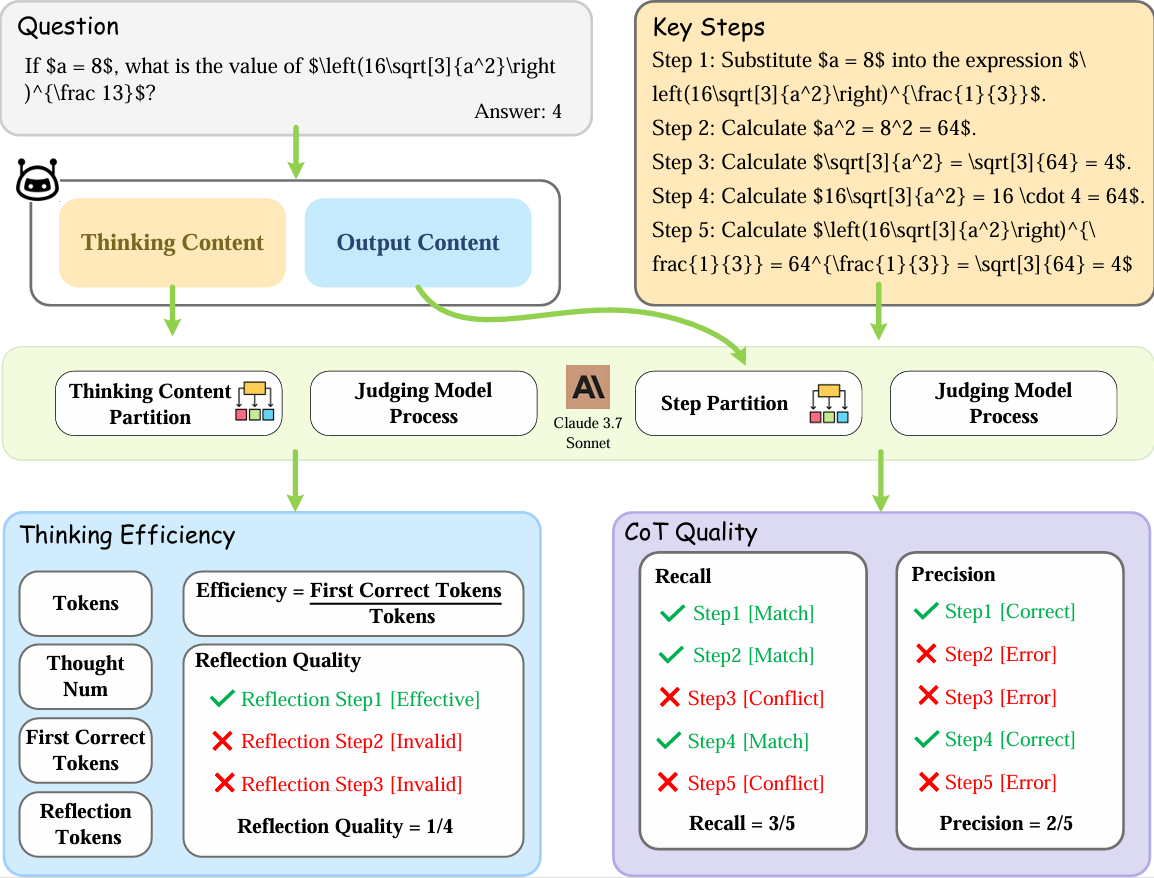
To address this issue systematically, we introduce Think-Bench, a benchmark designed to evaluate the thinking efficiency of large reasoning models (LRMs). We propose a new efficiency metric and conduct a comprehensive analysis of LRMs from multiple aspects, including the reasoning process and chain-of-thought (CoT) characteristics.
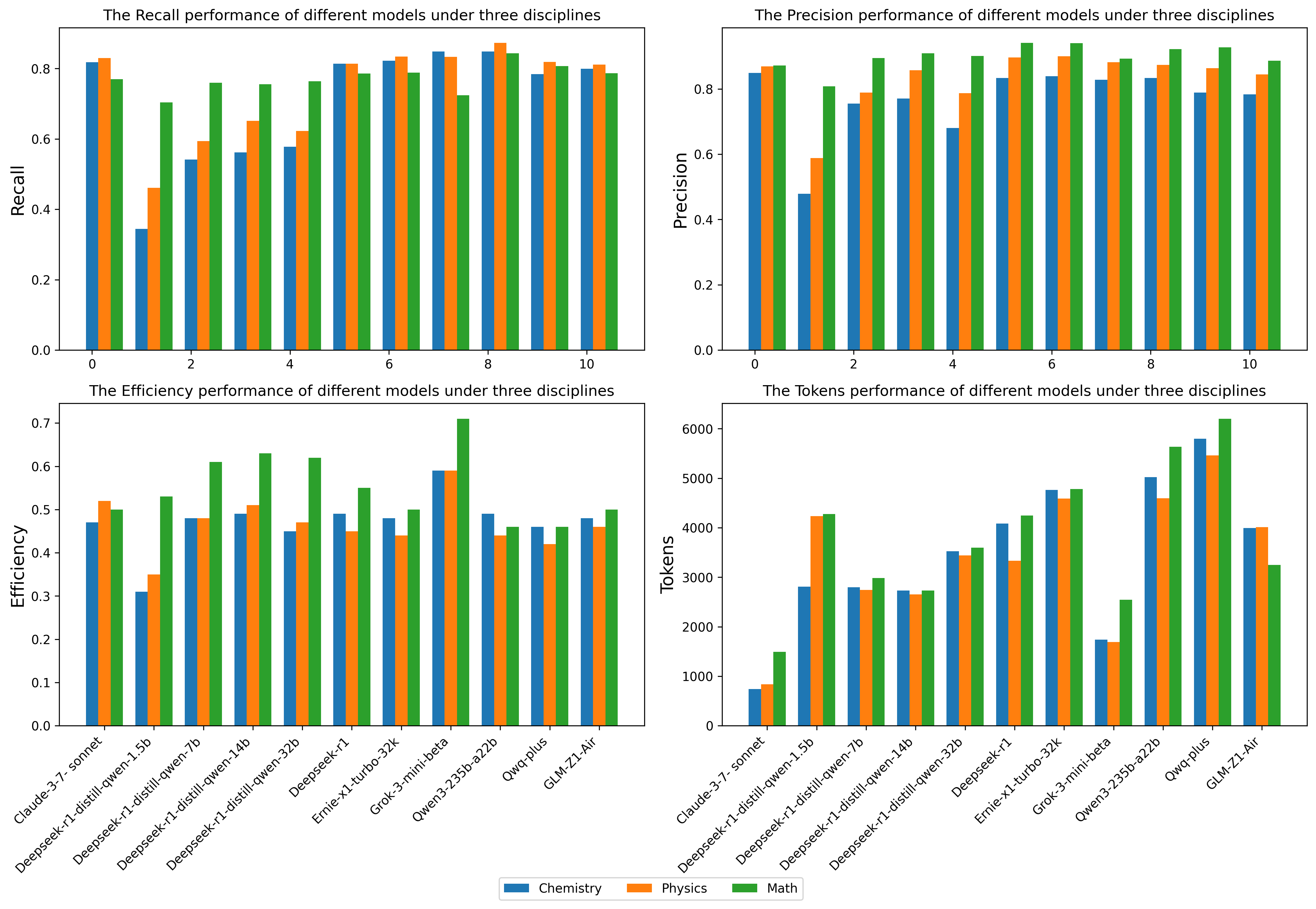
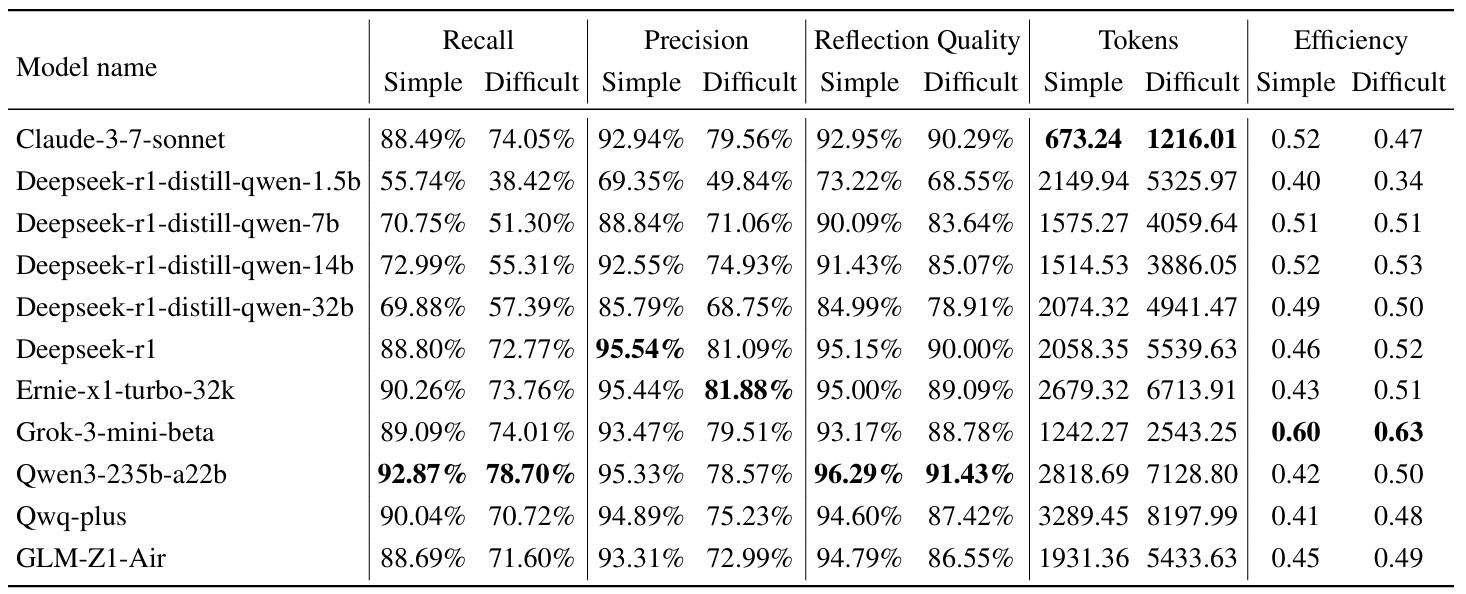
Leveraging the Think-Bench benchmark and a novel evaluation strategy, we conduct a comprehensive analysis of large reasoning models (LRMs), uncovering several key insights: (1) Most LRMs tend to overthink on simple tasks, generating unnecessarily long reasoning chains, while they show higher efficiency in hard problems; (2) There is a significant trade-off between efficiency and CoT quality among different models. Grok-3-mini-beta achieves the highest efficiency score, while models like Qwen3-235b-a22b and Ernie-x1-turbo-32k stand out in CoT quality; (3) Models show task heterogeneity in different disciplinary tasks. Mathematical tasks generally have high token consumption and low reasoning efficiency, while chemistry and physics tasks show higher reasoning efficiency and lower token occupancy rate. We hope Think-Bench serves as an important benchmark for optimizing the performance of large reasoning models in the future.
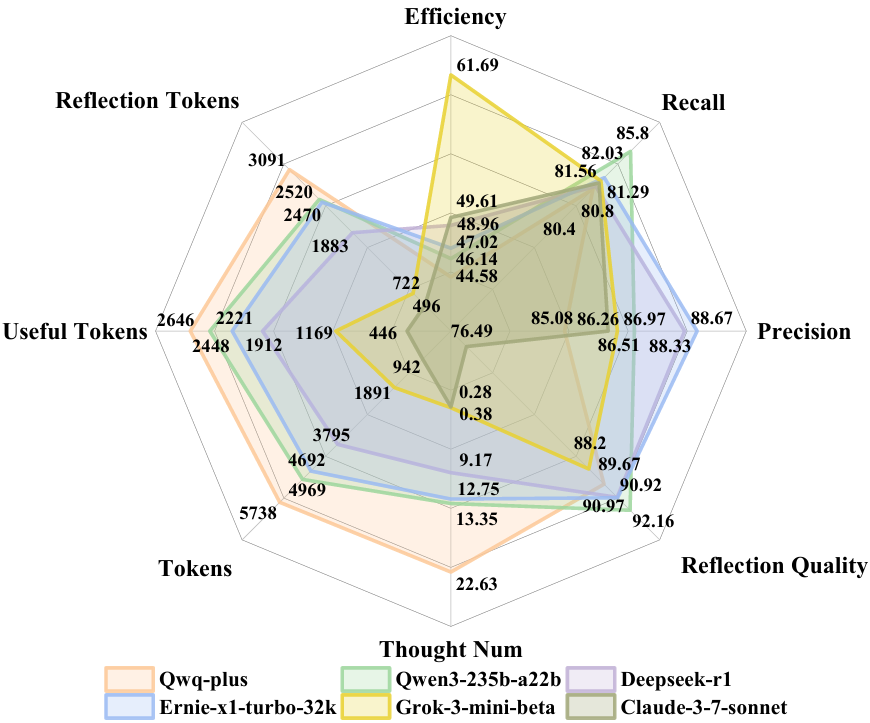
The performance of various LRMs onThink-Bench.